.png)

Содержание:
Паттерн feature-окружений называют по-разному: ondemand, review- или preview-окружения. Он нужен, чтобы приблизить среду разработки к продакшену, и позволяет разом избавиться от множества проблем, связанных с организацией разработки и переносом кода.
Но для создания feature-окружений и работы с ними ваш технологический стек должен быть достаточно мощным, чтобы обеспечить необходимую гибкость и динамичность. В этой статье я расскажу, как реализовать некоторые механизмы, необходимые для эксплуатации feature-окружений.

Почему стоит использовать feature-окружения
Во многих компаниях нет единого подхода к созданию окружений разработки кода или они складываются стихийно и бессистемно. Как правило, разработчики запускают и тестируют код на своих рабочих компьютерах, потом функциональность переносят в продакшен и возникает всем известная проблема: IT WORKS ON MY MACHINE.Десятый фактор методологии The Twelve-factor App рекомендует держать окружения разработки, промежуточного развертывания и рабочего развертывания максимально похожими.
Допустим, компания не следует этой рекомендации: разработчики используют собственные компьютеры с Docker Compose, а продакшн развернут в публичном облаке Kubernetes. В этом случае могут возникнуть разного рода проблемы.
Работа в режиме нескольких экземпляров. Если мы разрабатываем приложение cloud native и следуем методологии 12-factor app, то масштабируем приложение с помощью запуска новых процессов (согласно 8-му фактору). Зачастую разработчики об этом забывают, а локальные тестовые стенды редко моделируют эту особенность. В итоге получаются «плавающие» баги и непредсказуемое поведение приложения.
Например, программисты разрабатывают вызов в API, который позволяет «на лету» изменить уровень логирования системы. На тестовом стенде фича работает отлично, но после переноса на продакшн ее возвращают на доработку с ошибкой: «повышенный уровень логирования включается только для трети запросов». Она возникла из-за того, что в продакшене действуют три экземпляра приложения, а логирование изменяется только в одном из них — том, который принял вызов API.
Длительные соединения. В окружении разработки мы чаще всего имеем прямой доступ к приложению, а в продакшене оно может находиться за Ingress и несколькими балансировщиками нагрузки. При этом возникают проблемы с длительными соединениями и пропаданиями http-заголовков.
Например, облачные балансировщики часто обрывают запросы long polling из-за лимитов на длительность соединения, а для стабильной работы websocket через Ingress нужно настраивать sticky sessions. Если не учитывать это, приложение будет работать нестабильно, терять соединение или сетевые запросы.
Поддержка деплоя для нескольких систем. Если в компании используются две системы управления инфраструктурой, то периодические изменения в них нужно дублировать. Причем просто скопировать их нельзя: нужно сделать перевод из терминов одной платформы в термины другой.
Зависимые сервисы. Приложение часто работает не само по себе, а в связке со многими сервисами: очередями сообщений, базами данных, другими сервисами. Чтобы разрабатывать и тестировать новую функциональность, связанные сервисы нужно настроить и запустить в окружении разработки. Это часто нетривиальная задача: я сталкивался с компаниями, где новый сотрудник настраивал окружения разработки со всеми зависимостями на своей машине 1,5–2 недели.
Поддержка локальных окружений на ПК разработчиков. Одни программисты предпочитают Windows, другие Ubuntu, третьи работают на macOS разных поколений. В результате получается эксплуатационный ад, в котором почти невозможно сохранять единообразное и актуальное окружение разработки для каждого сотрудника.
Большинство из этих проблем и ошибок решается с помощью feature-окружений. Суть паттерна заключается в том, что программисты работают над новыми фичами в отдельных ветках Git (feature-ветках).
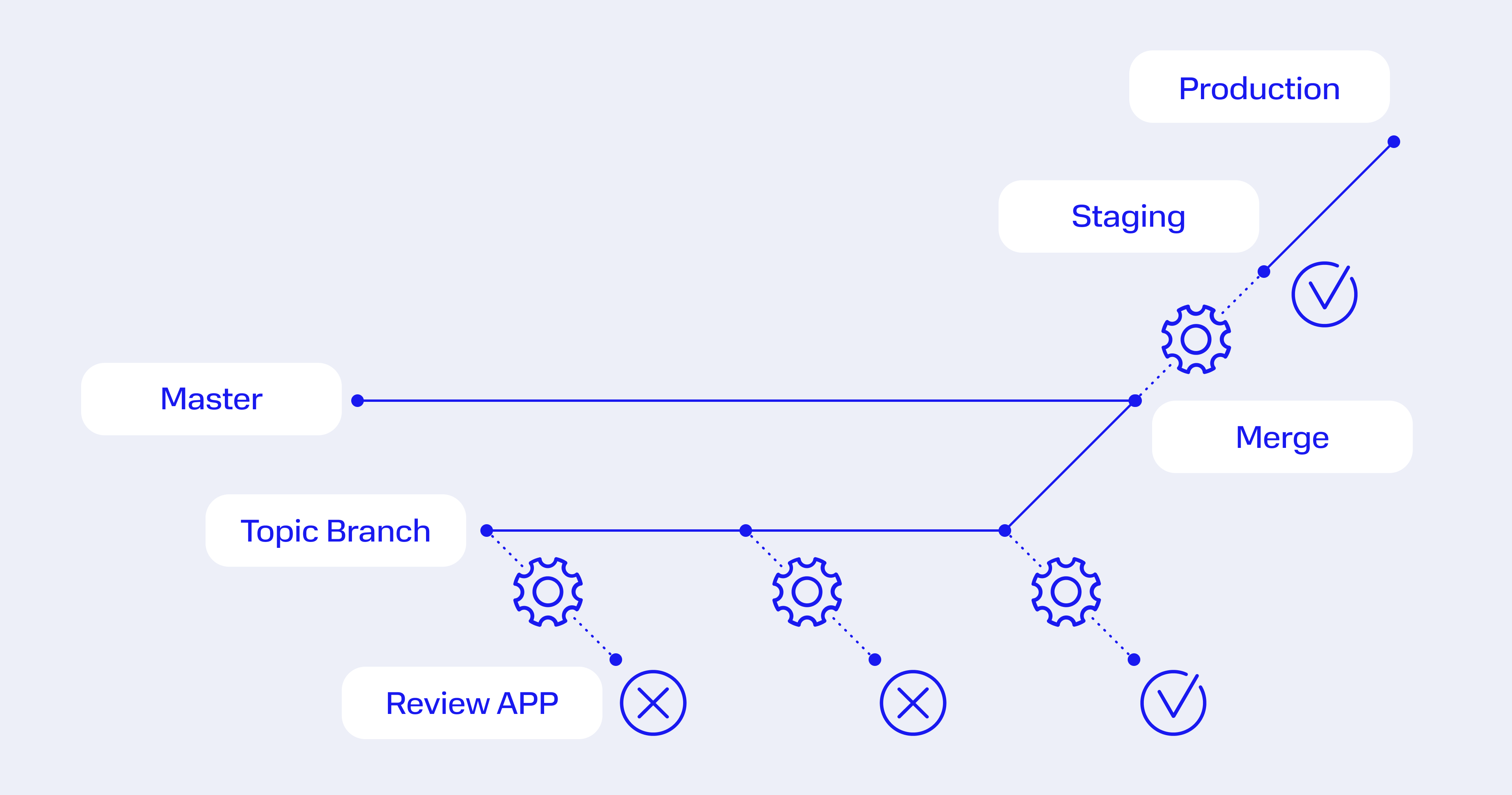
Артефакт в feature-окружении сразу доступен самому разработчику и его коллегам — другим программистам, QA-инженерам, постановщикам задачи. Это облегчает демонстрацию разработки и тестирование.
Как создать и настроить feature-окружение
Feature-окружения — это динамические, коротко живущие, гибкие сущности, поэтому ваш стек должен быть достаточно мощным. В этой статье я описываю, как создавать окружения при помощи Kubernetes, GitLab и HELM. На мой взгляд, этот стек обеспечивает максимальную мощность и гибкость.
Описанные действия можно выполнить с использованием других систем и инструментов, но в этом случае многие из описанных возможностей придется делать каким-то другим способом, а некоторые создавать с нуля.Методики разработки через Git — это отдельная большая тема, в которой есть свои особенности. Есть уже готовые методики, например Gitflow, GitLab Flow, TBD, но многие команды разрабатывают свои. В любом случае, если вы хотите использовать feature-окружения, нужно предусмотреть в процессе разработки возможность использования feature-веток.
GitLab — это пайплайны как код. Они описываются в YAML-файлах, которые хранятся в том же репозитории, что и код приложения, и фактически становятся его частью. Благодаря этому CI-процессы становятся более прозрачными и понятными для разработчиков.
Первый шаг пайплайна — сборка приложения, или билд (build). В нашем случае это Docker Image.

Стандартные переменные формируются из данных, которые характеризуют пайплайн. Именно этот механизм обеспечивает ту гибкость, которая позволяет динамически создавать артефакты и доставлять их в соответствующие feature-окружения. В принципе, этот механизм есть практически во всех CI/CD-системах, но в GitLab он наиболее развит.
В секции only указаны конкретные ветви репозитория, которые нужны для сборки feature-окружения. Их имена должны начинаться с префикса feature.
Секция except нужна, чтобы исключить дублирование пайплайна. Если для feature-ветки создан merge request, при пуше в нее пайплайн запускается дважды: для feature-ветки и для merge request. Чтобы этого избежать, последний исключается из триггеров пайплайна.
Следующий шаг пайплайна — деплой (deploy), или развертка feature-окружения:

Главная часть этого шага — вызов HELM Package Manager. HELM chart, который описывает инфраструктуру приложения, находится с ним в одном репозитории.
В вызове используются переменные, которые необходимы для деплоя. Рассмотрим их подробнее.
В секции environment указаны настройки для механизма трекингаокружений, который встроен в GitLab CI и веб-интерфейс GitLab.
Имя окружения (name) составляется динамически из имени ветки, на основе которой собран билд (CI_COMMIT_REF_NAME). Оно передается в деплой.
На базе имени окружения создается динамическая ссылка на окружение в домене компании для тестирования, на Ingress которого создана wildcard A-запись *.test.company.ru.
Итоговая ссылка имеет вид https://$CI_ENVIRONMENT_SLUG.test.company.ru. Благодаря динамической подстановке имени и wildcard А-записи можно публиковать любое количество окружений.
Секции only и except повторяют предыдущий шаг пайплайна (билд) и ограничивают ветви, для которых запускается деплой.
В секции variables в переменной CI_NAMESPACE формируется имя Kubernetes namespace, в которое мы будем деплоить релиз. Это имя уникально для каждой feature-ветки, состоит из имени проекта и имени ветки репозитория.
Теперь вернемся к секции script. В первой строке скрипта передаем в HELM имя namespace. Затем устанавливаем несколько значений:
-
global.env — имя окружения;
-
global.ci url — ссылка на окружение;
-
global.image_name — имя Docker-образа (сформировано на предыдущем шаге пайплайна);
-
global.gitlab.pipeline — ссылка на пайплайн.
Ссылка на пайплайн — best practice, которую я рекомендую. Ссылка передается в аннотации базовых объектов в Kubernetes и помогает при отладке приложения. Благодаря ей мы знаем, каким пайплайном задеплоен объект, можем посмотреть коммит и логи. Здесь она приведена просто для демонстрации разнообразия стандартных переменных GitLab CI.
Если в новом релизе не запустятся поды, HELM завершит работу с ошибкой, которую перехватит GitLab. Тогда у Job выката будет статус Failed, а у разработчика — понимание: что-то пошло не так.
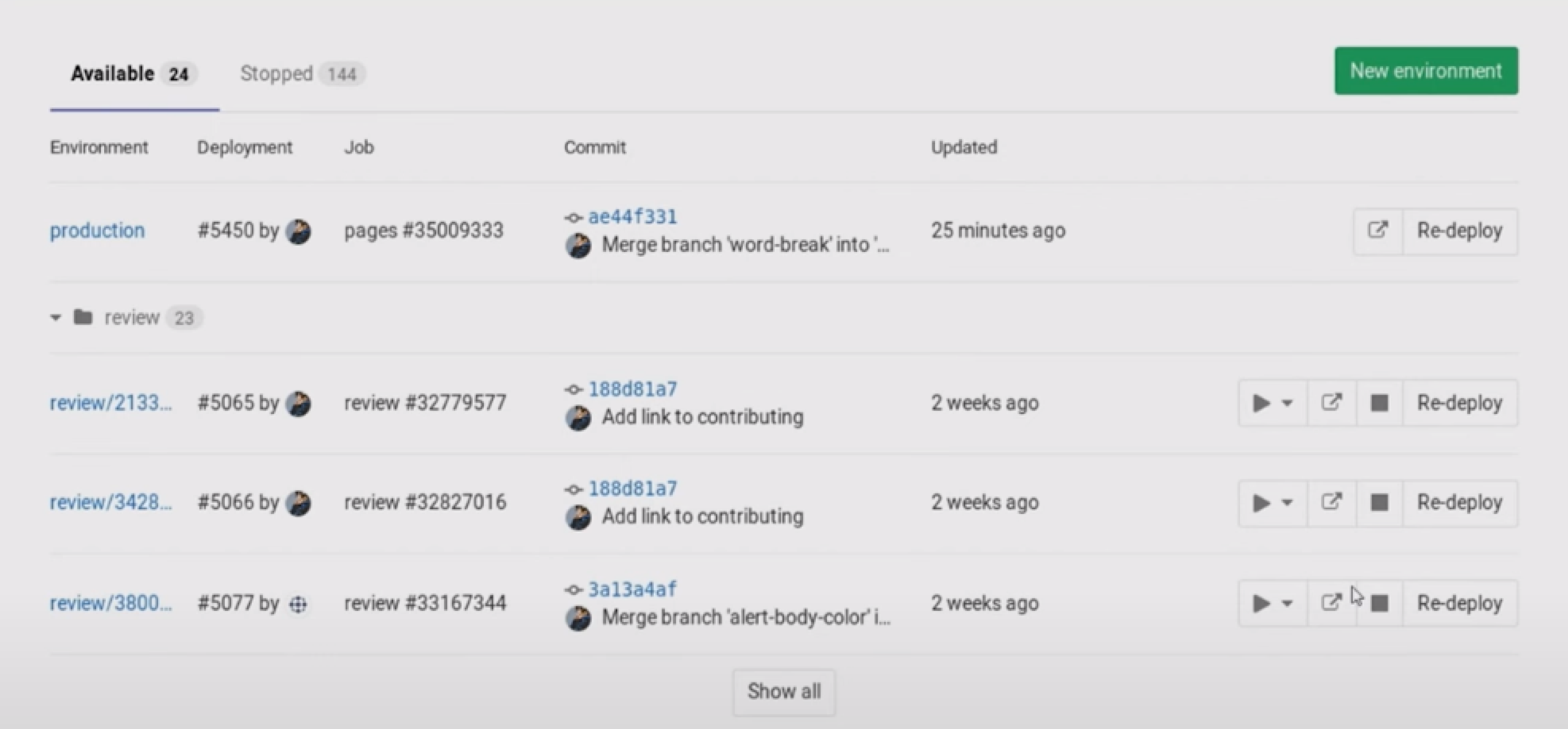
После вызова кода деплоя в секции Environments веб-интерфейса GitLab отобразится новое feature-окружение:
Как кастомизировать feature-окружение
Feature-окружения должны быть максимально близки к продакшену, но не идентичны с ним.Например, нормально, если сервисы персистентных данных (базы данных, очереди) в продакшене находятся на выделенных серверах, а feature-окружения — в Kubernetes. Такое решение менее стабильно и устойчиво к нагрузкам, но вполне удовлетворяет целям разработки и тестирования и позволяет экономить ресурсы.
Кроме того, feature-окружения обычно не нагружены, поэтому мы можем выделять на них меньшие лимиты/реквесты ресурсов.
Эти и подобные изменения задаются при помощи HELM Package Manager на этапе выката приложения. Тема деплоя с HELM достаточно обширна, поэтому в этой статье я затрону только необходимый и достаточный минимум его возможностей.
На этапе деплоя мы переопределили в HELM глобальную ссылку на feature-окружение. Чтобы задеплоить окружение именно на этот url, можно вызвать соответствующее значение в коде Ingress-контроллера.
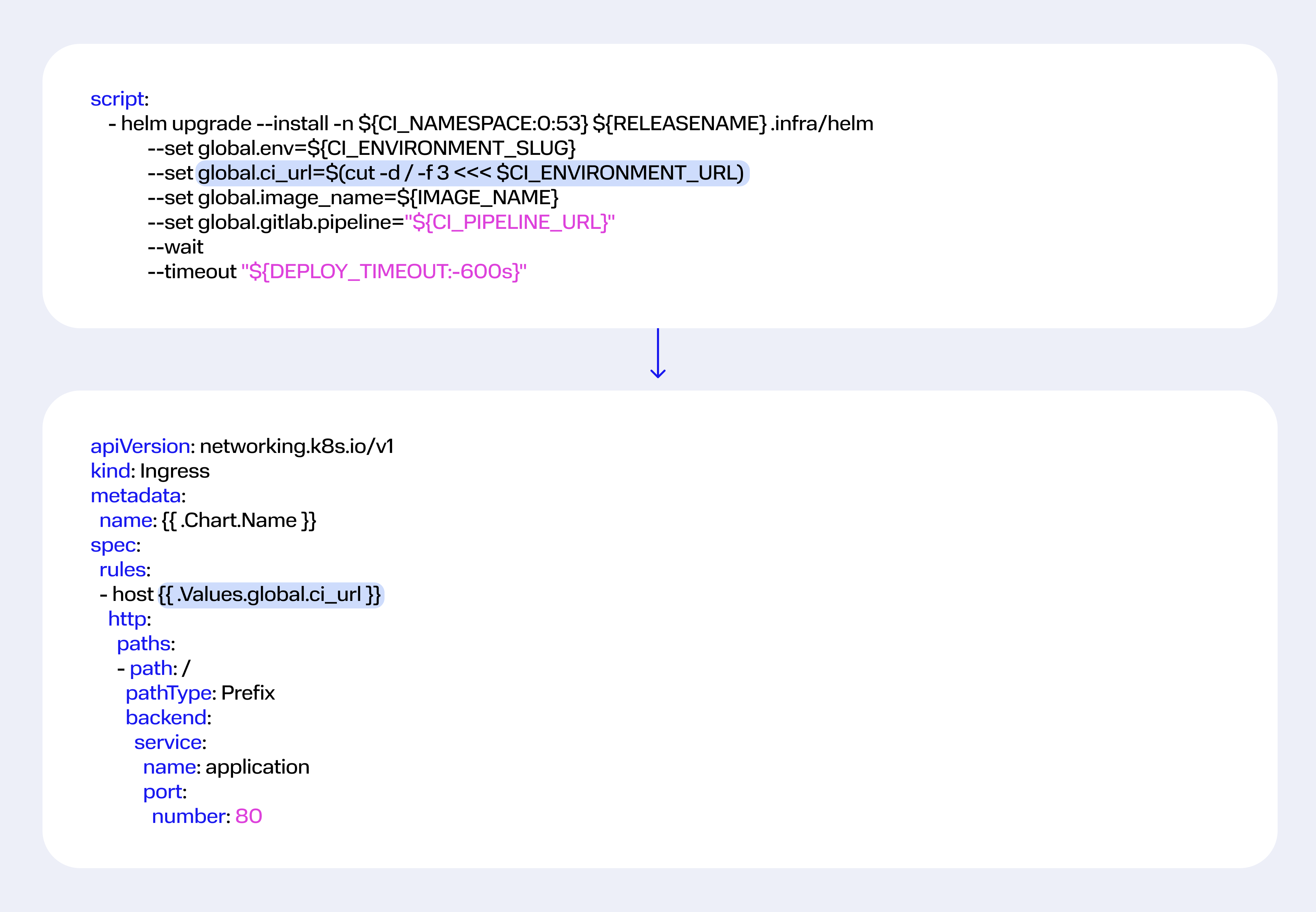

HELM может анализировать переданные ему значения и добавлять или не добавлять код в YAML-файл в зависимости от их содержимого.
Например, на шаге деплоя мы переопределили глобальное значение global.env для имени окружения. Если имя начинается с feature, в релиз добавится код с описанием StatefulSet для PosgreSQL:
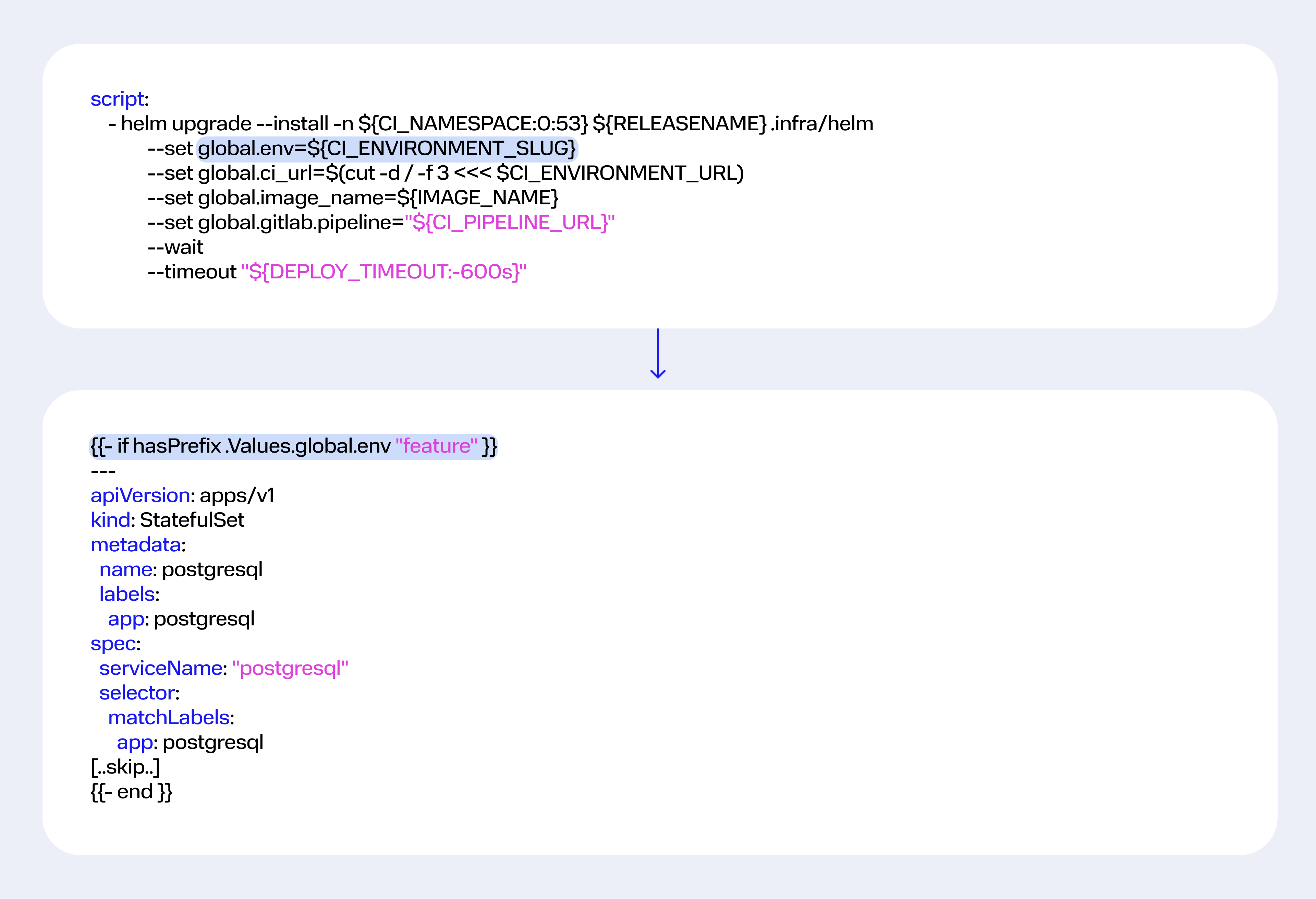

Использование сабчартов — это продвинутый уровень эксплуатации HELM Package Manager, но они бывают полезны. Например, если у вас микросервисная архитектура, вы можете сделать репозиторий HELM-чартов с типовыми инфраструктурными сервисами и значительно минимизировать код в чарте приложения.

Как загружать тестовые данные в feature-окружения
Как правило, в окружении невозможно вести разработку и тестирование, если в нем нет тестовых данных: пользователей, паролей, клиентов, справочников. Загрузить тестовые данные в окружение можно тремя способами: миграции/фикстуры, отдельная задача в GitLab CI или специальный Docker Image.1. Миграции/фикстуры.
Миграции — это стандартное средство для поддержки актуальности базы данных и ее структуры. А фикстуры — это программный скрипт, который наполняет базу с готовой структурой тестовыми данными. Это достаточно близкие подходы, поэтому рассмотрим их вместе.
Для загрузки миграций/фикстур в окружение, можно использовать механизм HELM Lifecycle hooks (хуки). С его помощью HELM создает или удаляет примитивы в Kubernetes в заданный этап выката релиза. Чтобы использовать хуки, нужно добавить в код секцию со специальными аннотациями. Ниже пример Kubernetes Job, которая выполняет прогон миграций.

Hook-weight устанавливает приоритет запуска хуков. Например, с приоритетом 5 мы прогоняем миграции, а 10 — фикстуры.
Hook-delete-policy определяет, что нужно удалить выполненный Job, то есть очистить namespace от лишних объектов.
2. Отдельная задача в CI.
В пайплайн можно добавить отдельный этап для загрузки тестовых данных.

HELM на этом этапе нужен для трекинга релиза с помощью ключа --wait. Он следит за тем, чтобы Job выполнился корректно. Таким образом разработчик будет уверен, что база актуальная и возможные проблемы в работе кода с ней не связаны.
after_script выполнится после основного скрипта, снимет логи с контейнера Job и очистит namespace от объектов, созданных основным скриптом.
3. Специальный Docker Image.
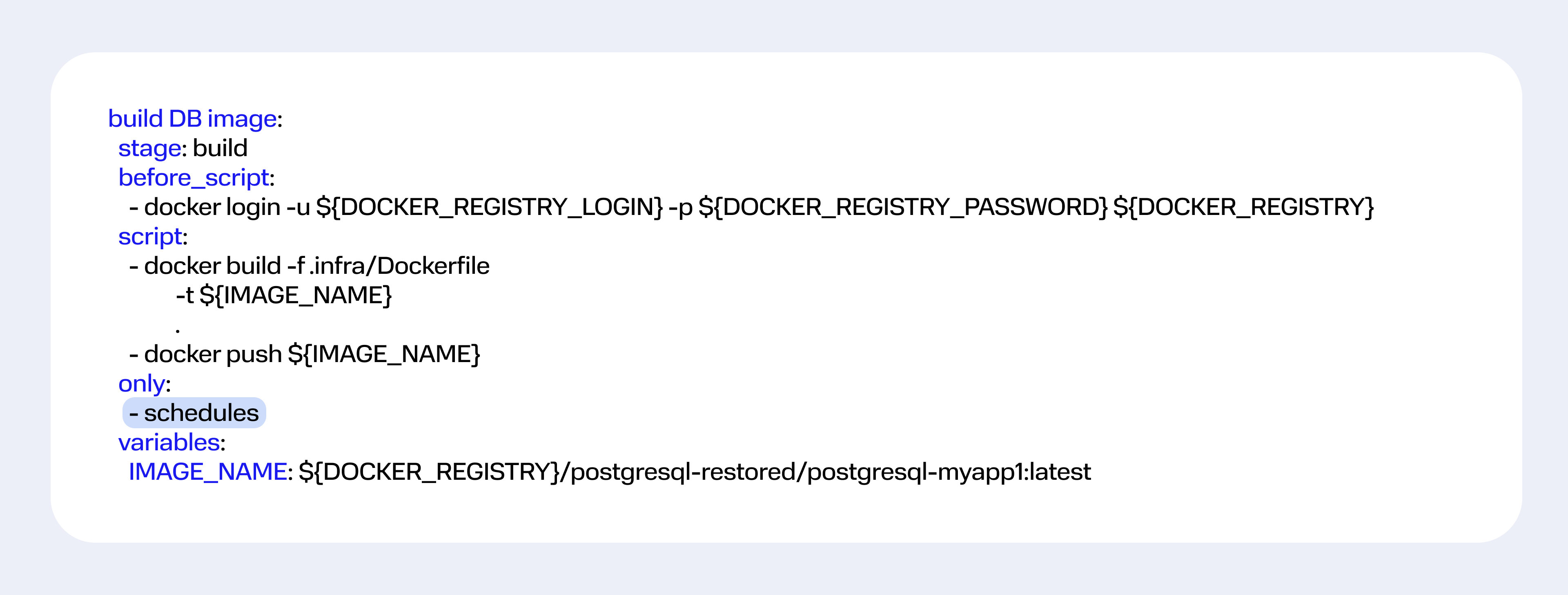
Можно создать Image, который уже содержит тестовые данные, и на его основе запустить нужные нам сервисы. Для этого надо скачать дамп, развернуть его на файловую систему Image и записать в Docker Registry с тегом latest. Тогда каждое новое развертывание окружения будет актуализировать базу, если в коде указан ключ imagePullPolicy: Always.
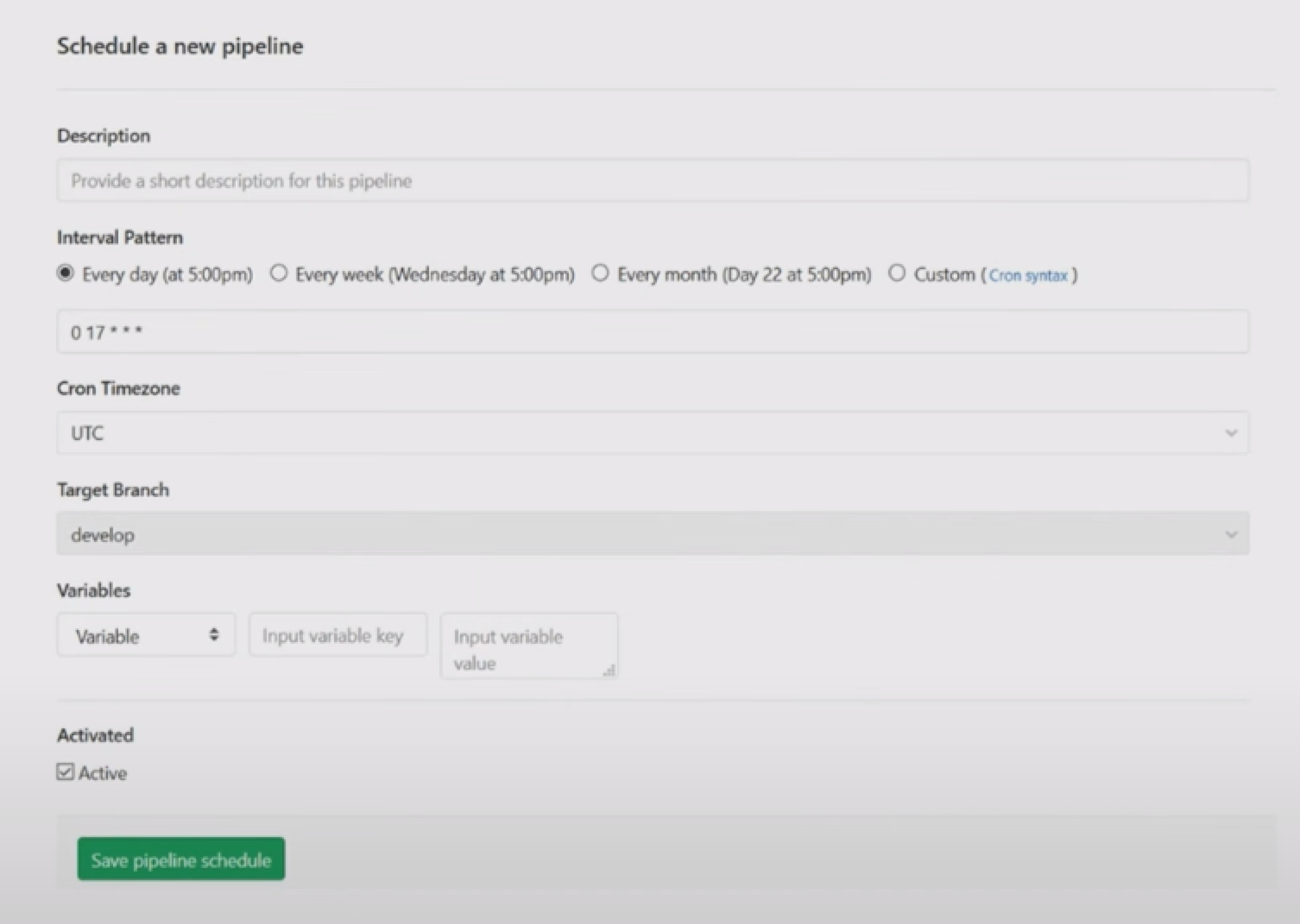
Вопрос в том, как создавать такие имиджи. В GitLab есть возможность создать запланированные (Scheduled) пайплайны. Для этого в интерфейсе GitLab нужно сделать Schedule (расписание) для пайплайна и указать необходимые параметры запуска: период, ветку репозитория, переменные.
Работа с мультирепозиториями
Иногда приложение работает не в одиночку. Классический пример — frontend и backend, когда первый не функционирует без второго. Кроме того, становится все более популярной микросервисная архитектура, в которой достаточно часто нужно запускать основной микросервис и несколько связанных.Стандартный подход при тестировании в подобных случаях — разработка mock-сервисов. Это заглушки, которые дают базовые ответы на типовые запросы. Создавать mock-сервисы достаточно трудоемко, разработчики тратят на них много времени. Вместо этого можно развернуть связанные сервисы в feature-окружении одновременно с основным.
Во-первых, деплой связанных сервисов можно сделать через вызов GitLab API. Например, в секции after_script.

Далее через указание variables передаем нужное количество переменных для настройки вызываемого пайплайна, чтобы он «встроился» в наше feature-окружение.
Затем передаем данные для запуска пайплайна в конкретной ветке репозитория связанного сервиса (ref=develop).
Но часто бывает, что эту ветку нужно менять для запуска нашего микросервиса на определенной версии связанного микросервиса.
Для этого можно создать специальный файл, в котором указывать нужную нам ветку:
ref=$(cat ./branchname || echo develop)
Или можно задать динамическое имя через переменную GitLab:
ref=$BRANCH_NAME.
Тогда ветку можно будет задавать через механизм ручного запуска пайплайнов GitLab, в котором можно переопределять переменные.
Раньше мультиокружения были только в платных тарифах. Подобный жизненный цикл фич характерен для GitLab: новая платная функциональность через некоторое время становится доступна всем.

После запуска этой задачи в наш пайплайн добавятся шаги из связанного, и мы сможем отслеживать, как они проходят.
Работа с окружениями
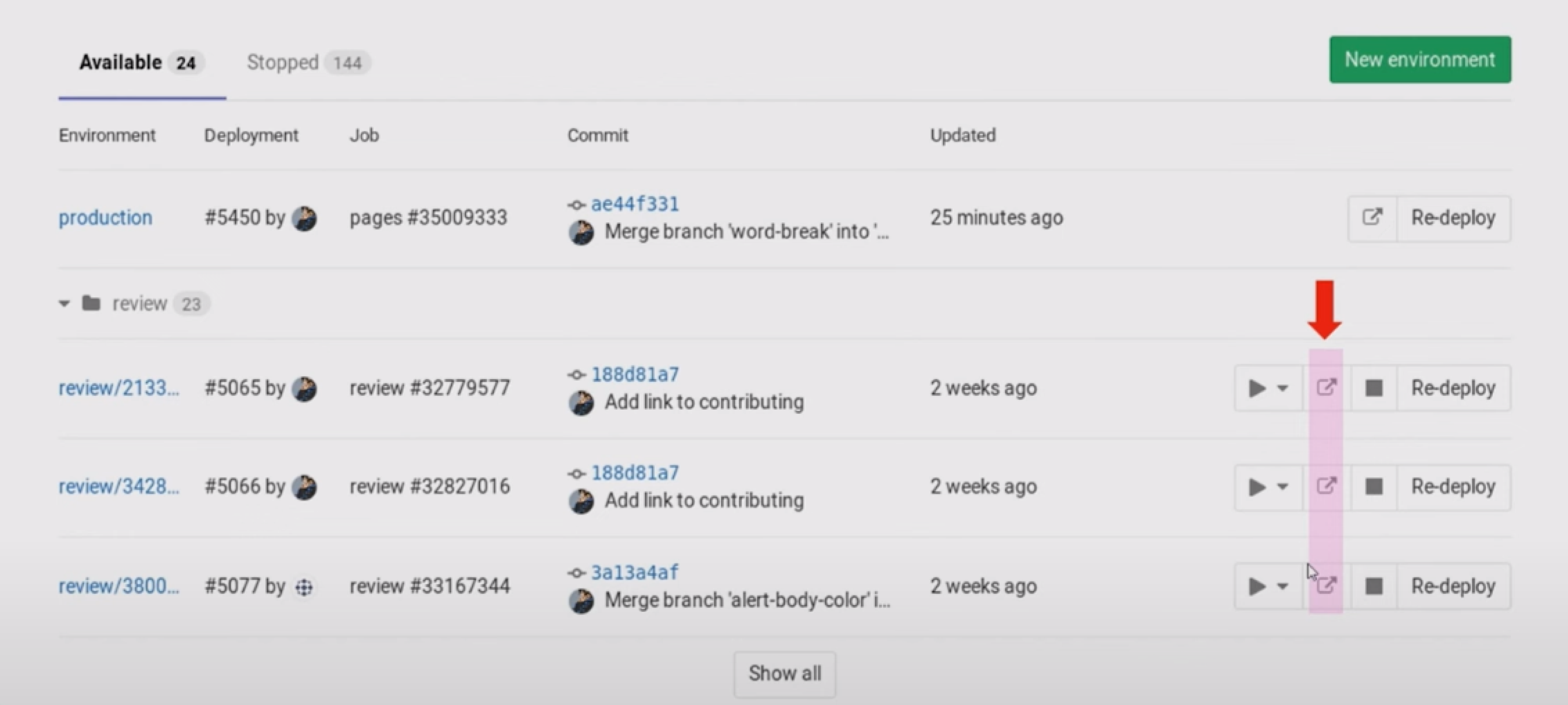
Когда feature-окружение полностью готово, все нужные сервисы развернуты, а тестовые данные загружены, пора начинать работу с ним. Для этого нужна ссылка на окружение, которую можно получить двумя способами:-
На странице Environments в веб-интерфейсе GitLab. После деплоя у каждого окружения появляется кнопка со значением из секции environment: url из файла CI для перехода по ссылке.
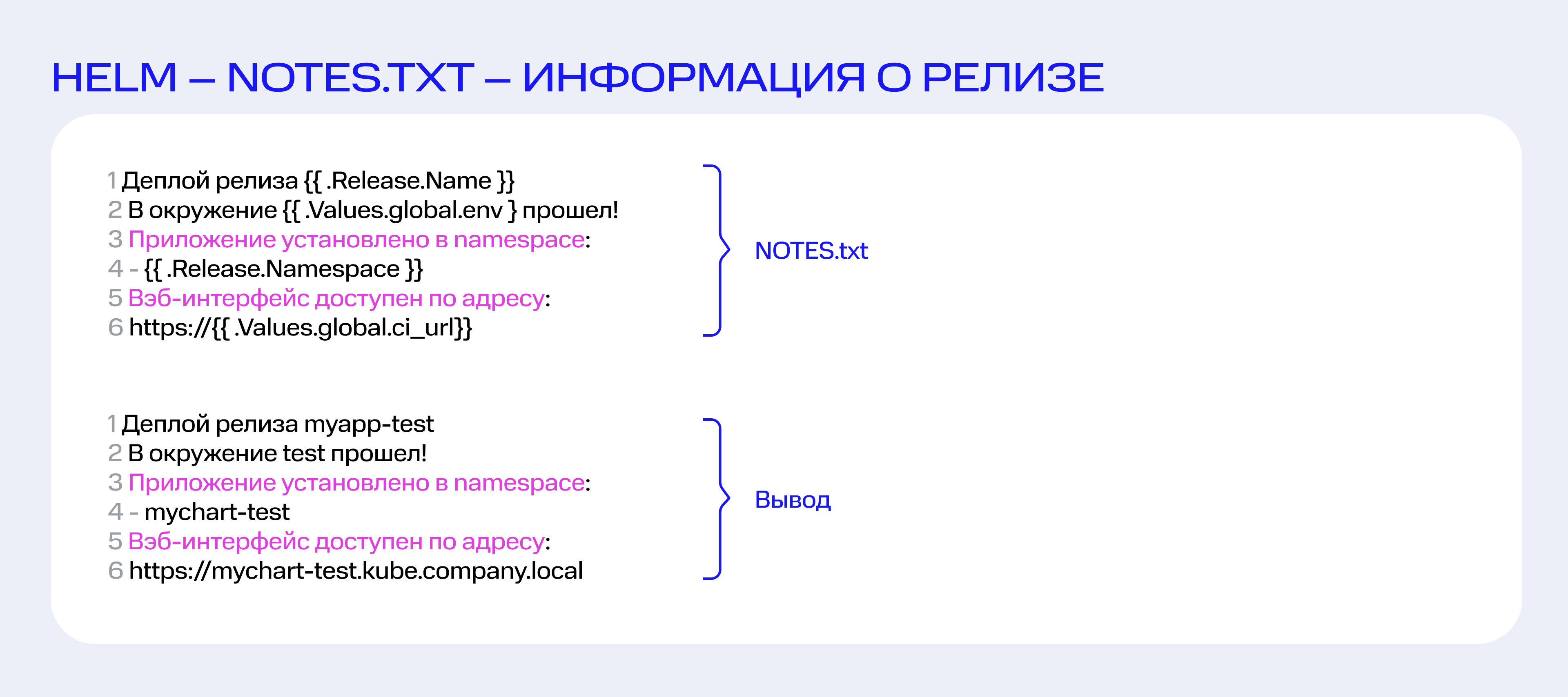
Дать доступ к namespace можно при помощи веб-интерфейса наподобие Kubernetes Dashboard.
Очистка окружений
Последний этап работы — очистка старых или ненужных окружений и высвобождение ресурсов. Хотя для запуска feature-окружений используется не так много ресурсов, очевидно, что их не может быть бесконечно много.Для очистки feature-окружения можно использовать механизмы GitLab. Для этого в задаче деплоя нужно описать ключи on_stop и auto_stop_in в секции environment.

Задачу остановки нужно описать отдельно:

Строка when: manual указывает, что задача удаления — это ручное действие.
Последняя особенность этого пайплайна — переменная GIT_STRATEGY: none. Это значение отключает получение кода из Git-репозитория. Вместо него используется тот, что уже есть в кеше. Без этой настройки пайплайн может ломаться на невозможности получить код в случае, если он запускается после мержа feature-ветки. При наличии соответствующей опции на merge request, эта ветка может быть автоматически удалена.
Задачу остановки можно запустить по кнопке из пайплайна или в окне просмотра окружений. Если в environment задачи деплоя описан ключ on_stop, в списке окружений появится соответствующая кнопка.









